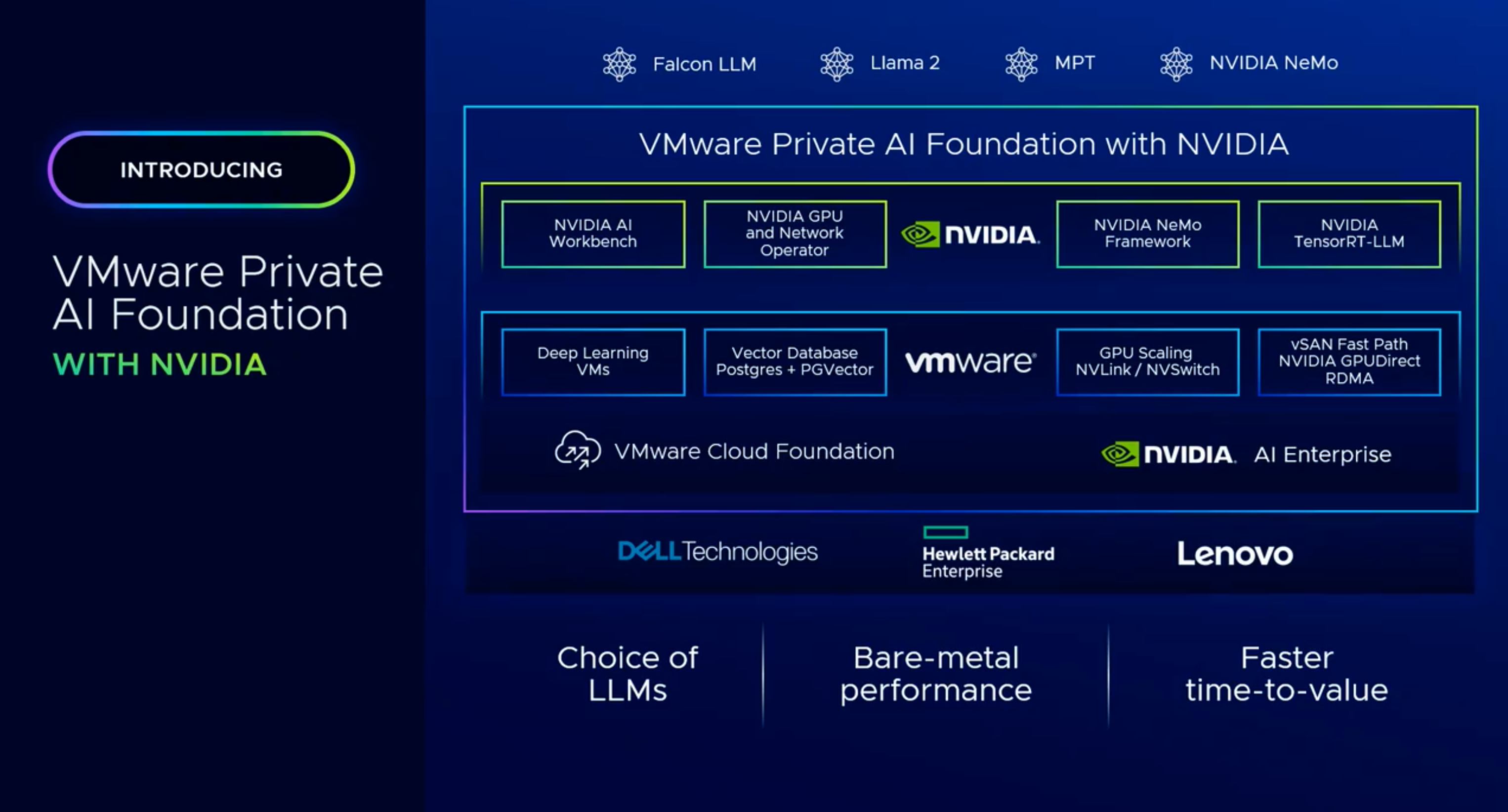
VMware by Broadcom recently announced a dramatic simplification of their product portfolio to unlock more value from customer investments. The cost of VMware Cloud Foundation (VCF), the flagship enterprise hybrid cloud stack, was slashed, and VMware vSphere Foundation was introduced.
‘The new VMware vSphere Foundation delivers a more simplified enterprise-grade workload platform for mid-sized to smaller customers. This solution integrates vSphere with intelligent operations management to provide the best performance, availability, and efficiency with greater visibility and insights’. You can read the full announcement here.
Many customers already get huge value out of Aria Operations alongside vSphere and their multi-cloud environments. For those that don’t, this post will start by outlining 3 use cases that fit almost any organisation and persona, from VI admin through to CIO. The second part of the post will cover the easy setup of Aria Operations to help customers get up and running in no time, either with the new licensing model or using a free evaluation.
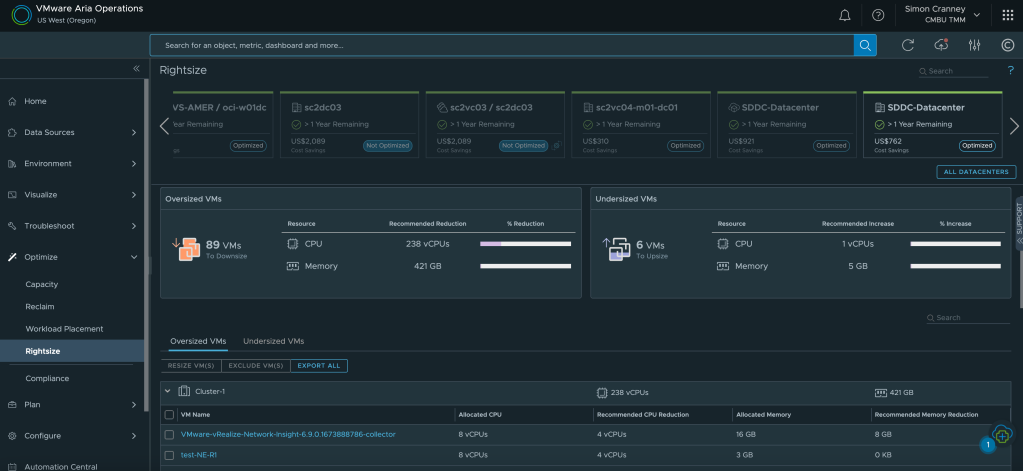
1. Do More With Less: Capacity Management
Often capacity and procurement planning is done manually, ad-hoc, and as a best guess estimate. I’ve been there myself, as a VI admin I used to think I knew all the workload demands and upcoming project requirements for the infrastructure I was responsible for. That knowledge is still relevant, but can be enhanced with accurate data.
Aria Operations delivers immediate benefits through optimisation and waste management. Oversized, hidden, or stale resources can be identified and dealt with accordingly. The context you have as a VI admin complements that information; a simple example is a clinical application that may not utilise its full resource allocation, but still requires it to meet third-party application support contracts. These workloads can simply be tagged and/or hidden from rightsizing. As well as oversized workloads, resources can be reclaimed from orphaned disks, snapshots, and idle or powered off VMs. Another common scenario is that infrastructure teams are asked to throw more virtual resources at application issues or poorly written code, which in some cases can compound the issue, especially when over allocating CPU. Detailed performance tracking and evidence backed recommendations can be used to justify workload sizing.
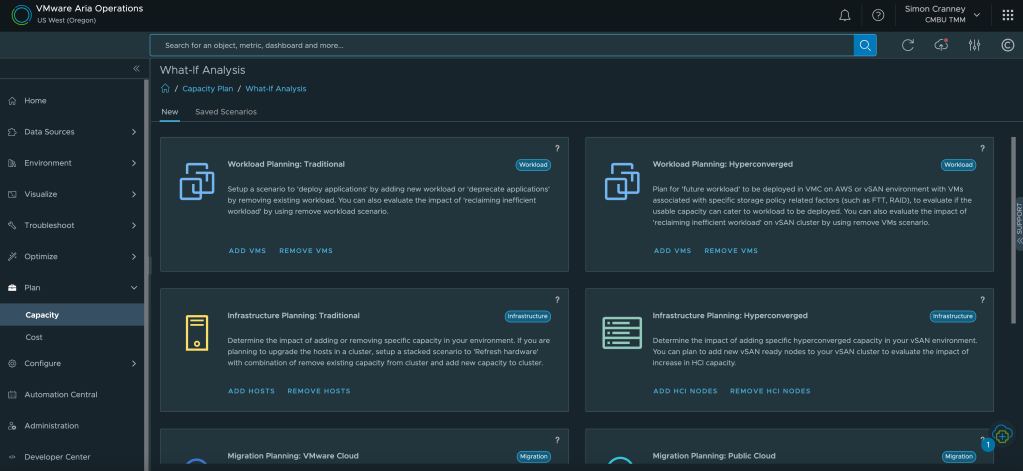
One of the most useful features of intelligent capacity planning is to visualise what-if scenarios. This could be a data centre move, hardware consolidation, architecture change, or cloud migration. What-if scenarios show the infrastructure requirement or impact of proposed and considered changes. Outputs can be exported as reports which serve as evidence for budget requests or change approval.
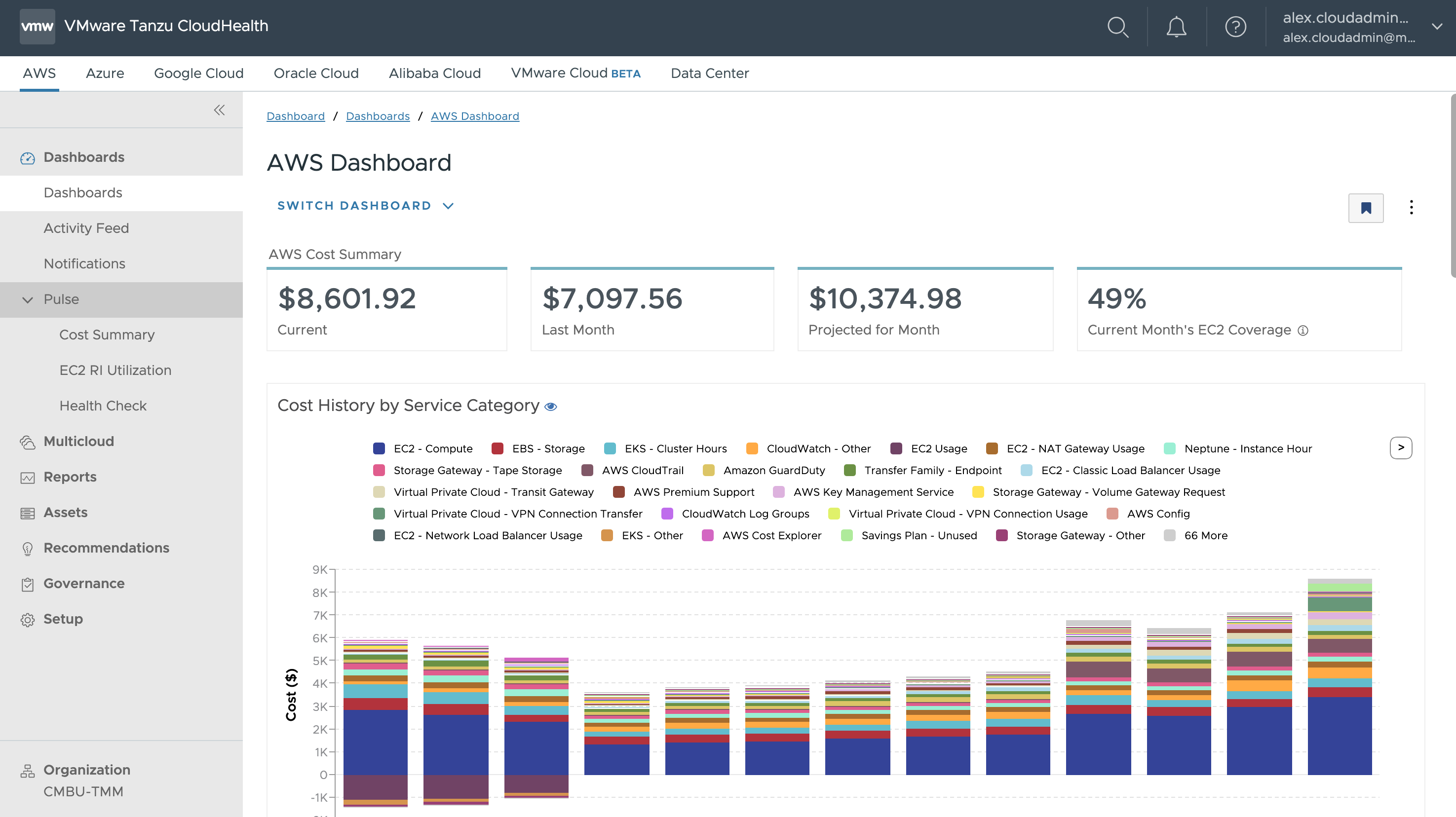
The final headline feature on this point is the cost visibility and show-back capability in Aria Operations. IT can raise cost awareness for other departments when they request new or increased resources. Many service owners do not realise the total cost to the business of an IT resource, and whilst not all organisations want to cross-charge, there is huge value in tracking and showing these costs to help reduce overall utilisation. Furthermore, the what-if scenarios mentioned above also include cost comparisons for infrastructure changes. You can add your own custom costs for facilities, employees, or enterprise agreements to ensure accurate figures.


2. Reduce Unplanned Downtime: Monitoring & Troubleshooting
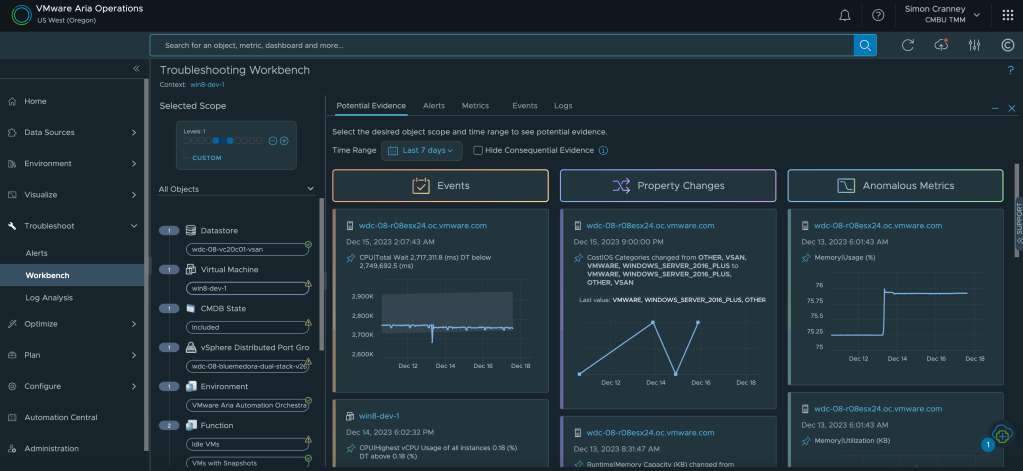
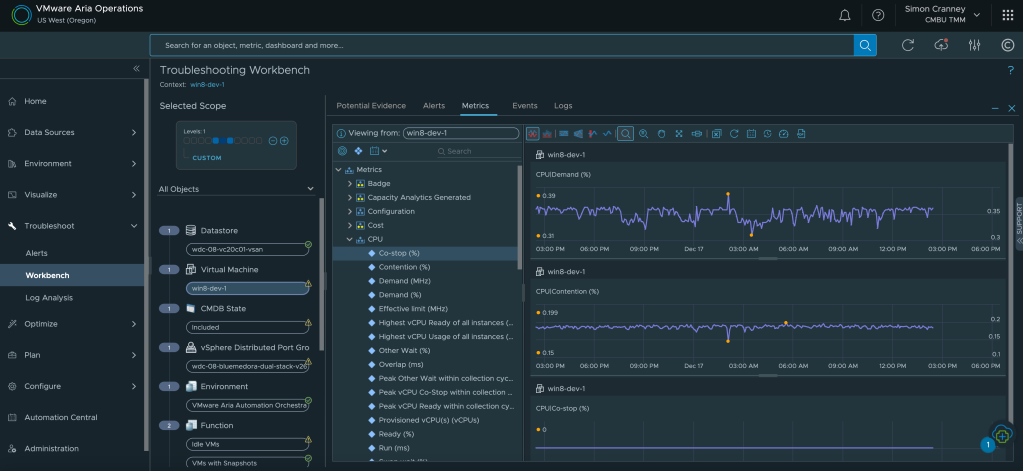
VMware vSphere on its own provides great value as a foundational hypervisor, for management, availability, and resource scheduling. When it comes to troubleshooting, due to the complexity and interoperability of enterprise IT, multiple personas and information sources can be involved. Often this means supplementing vCenter information with command line or third-party tools, such as monitoring or log analytics, which can slow down the time to fix and lead to a blame culture between teams.
With Aria Operations, IT operations can resolve issues faster with actionable insights, overall and individual object health, and deep dive pathways into correlated metrics, data and logs. Management packs and integrations enable the build out of a complete application and infrastructure stack view, to identify bottlenecks or potential issues from a single source. What’s more, the management packs for applications and databases, previously licensed as add-ons, are now included in the software foundations mentioned at the start of this post. You can read more about VMware provided management packs in the Aria Operations Integrations Documentation.
The additional visibility afforded to VI admins is easily extended to the wider organisation. Custom dashboards and automated reports are great ways of sharing information and status updates with business units, senior management, and service management teams. There are plenty of built-in dashboards for monitoring and examining the VMware environment out of the box, but the VMware Sample Exchange also has a bunch of community developed dashboards and code samples to get you started.
As well as health and performance, Aria Operations provides policies, reports, and alerts against compliance and regulatory benchmarks, such as the vSphere, vSAN, NSX, and VCF security guides, or the PCI and ISO27001 hardening guides. Just like dashboards and reports, custom compliance benchmarks can also be created. Together these features help track and evidence items for audit and cyber risk assessments such as the Cyber Assessment Framework (CAF).


3. Track Your Decarbonisation Goals: Sustainability
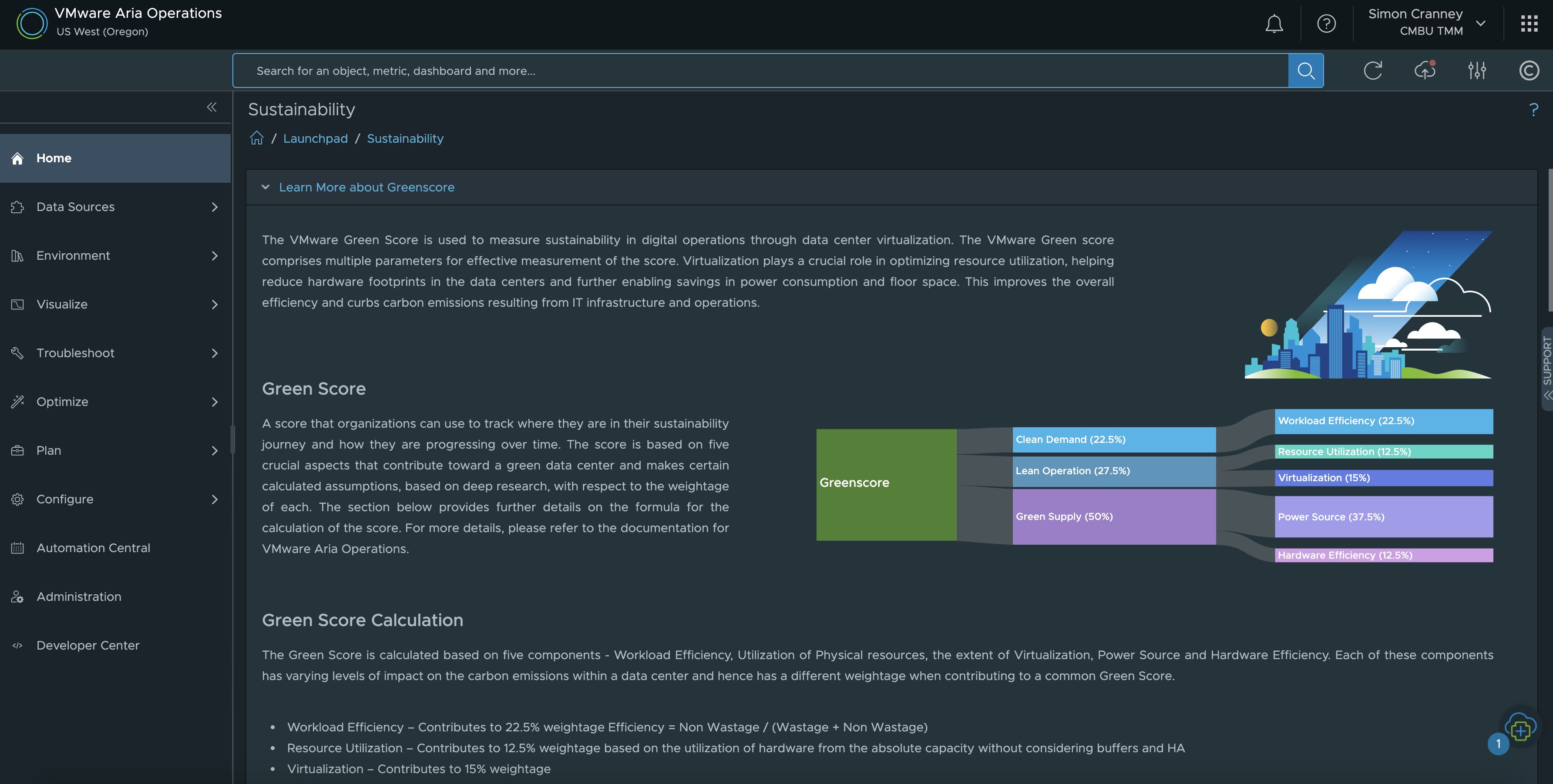
Another priority for many organisations is enhancing their Environmental, Social and Governance (ESG) credentials. The Aria Operations Green Score allows customers to directly gather and track information on the environmental sustainability of their on-premises infrastructure. This feature provides recommendations to optimise energy usage and carbon footprint. The score factors in workload and hardware efficiency, resource utilisation, virtualisation rate, and power source. You can read more about this topic and VMware’s own ESG commitments in the blog post Accelerate Sustainability Targets with VMware.
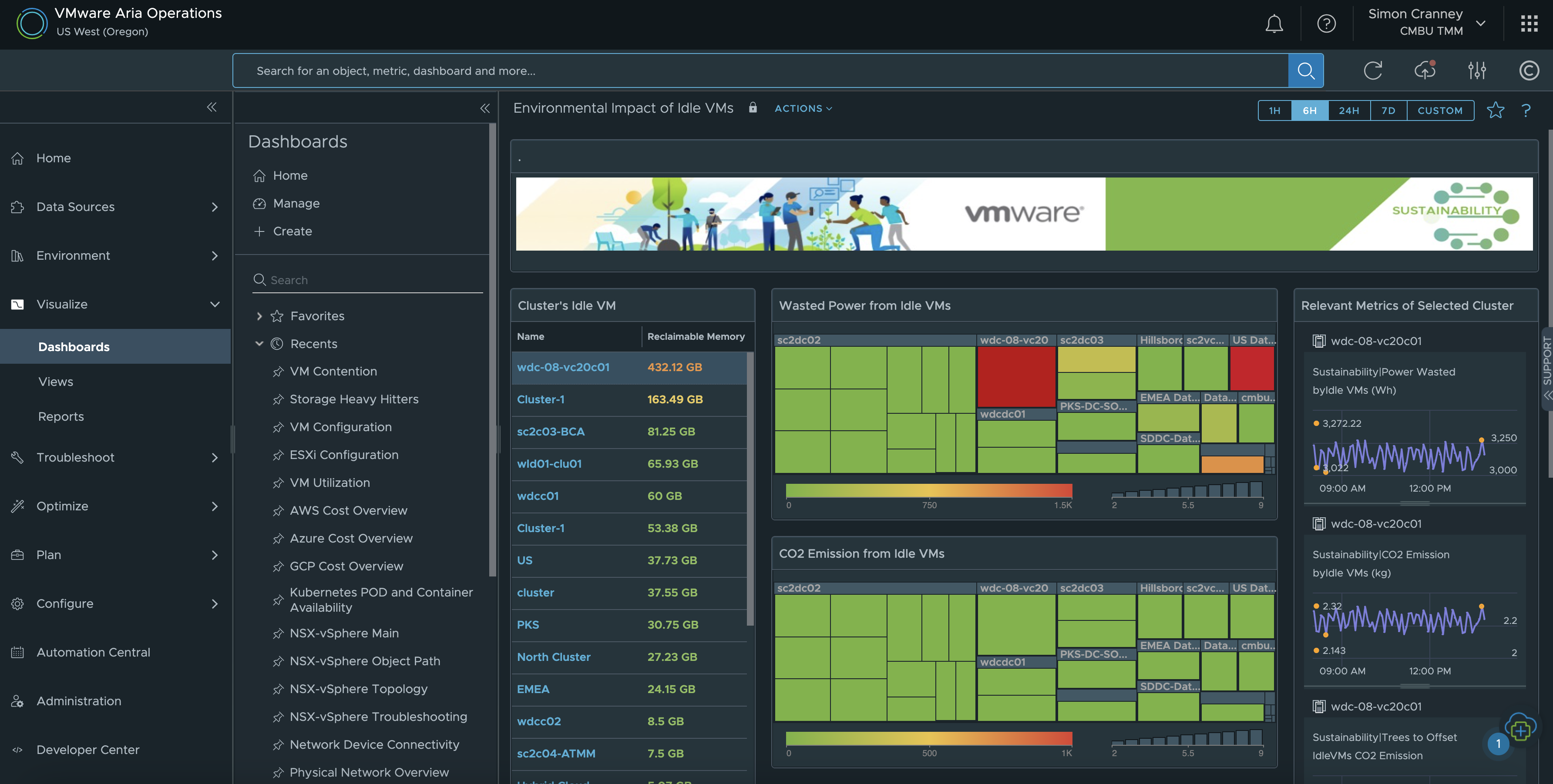
The built-in Aria Operations Sustainability Dashboards provide visibility into sustainability optimisation and emissions reduced by using VMware technologies. The available dashboards at the time of writing include: carbon transparency, carbon efficiency with virtualisation, environmental impact of idle VMs, and green supply. This is complimentary to existing features that already help customers manage their energy consumption such as workload right-sizing, resource reclamation and capacity management.




Installing Aria Operations
To get up to speed on Aria Operations, I recommend following the VMware Aria Operations: Journey To Success walkthrough which explains how to use and get the most out of each feature. The VMware Aria YouTube Channel and VMware Hands-on Labs are also great free training resources.
If you don’t have a license for Aria Operations you can sign-up for the 60-day evaluation. For a more detailed setup guide and topology overview consult the Installing VMware Aria Operations and Reference Architecture Overview sections of the VMware Aria Operations product documentation.
As always, before installing you should review the appropriate release notes and check the Product Interoperability Matrix. All deployments start out with the Aria Operations Manager master node. For the purposes of this setup, and for some small to medium production environments the master node is generally sufficient to manage itself and perform all data collection and analysis operations. You can build in high-availability and multi-site configurations if required using clustering the installation and topology guides linked above.
Appliance Deployment
- Download the Aria Operations Manager OVA from Customer Connect here.
- Allocate a static IPv4 address for the master node and a Fully Qualified Domain Name (FQDN) with forward and reverse DNS entries. Whilst the DNS entry is not strictly required for deployment, it is good practice to have ready.
- You will need access to the vCenter Server to deploy the OVA. An account is also required to register the vCenter connector; you can use a dedicated service account, or a built-in account such as administrator@vsphere.local. The account can be changed afterwards if needed.
- Log into the vSphere client and deploy the OVA (right click the target host or cluster and select Deploy OVF Template). The deployment wizard prompts for the usual options like compute, storage, and IP address allocation. You will be asked for the appliance size based on the sizing guidelines displayed on screen, you can also find the appliance requirements in the VMware Aria Operations Sizing KB or the more advanced interactive Aria Operations Sizer.
- Do not include an underscore (_) in the hostname.
- When the deployment is complete power on the virtual machine.
Appliance Setup
- Browse to the appliance FQDN or IP address to complete the setup. You can double check the IP address has applied correctly from the virtual machine page in vSphere or the remote console.
- For the purpose of this setup, and a single Aria Operations Manager deployment, select express installation. The Aria Operations Manager appliance will be set as the master node, this configuration can be scaled out later on if required. For larger environments and additional settings like custom certificates, high availability, and multiple nodes select the new installation option.
- Follow the on-screen prompt to set an administrator password and click finish to apply the configuration. A loading bar will appear, this stage can take around 15 minutes.
- When the setup is complete login with the username admin and the password set earlier.
- Accept the End User License Agreement (EULA), and enter the license information. You can leave this blank for now or use an evaluation key if you have one. Select or deselect the Customer Experience Improvement Program (CEIP) option, then click finish.
Add vCenter Server
- Now Aria Operations is ready to use we can go ahead and add the vCenter Server(s). From the launchpad, expand data sources and integrations, click add and select vCenter as the account type.
- Enter a display name for the vCenter account, and add the vCenter Server FQDN or IP address. Since we deployed a single Aira Operations Manager use the default (built-in) collector group. Test the connection, enable vSAN if required from the vSAN tab, and then click add.
- Give the vCenter account a few minutes to sync up, the status should change to OK. Back at the launchpad a prompt is displayed to set the currency; configurable under administration > global settings > cost/price > currency.
- Permissions are inherited from vCenter by default, but you can also add your corporate Identity Provider under administration.
- Once a data source is being collected and analysed, typically I would leave for at least 7 days before acting on any of the information presented. The more data available to Aria Operations the more accurate the recommendations will be.