The uptake and importance of both cloud and data services has increased significantly over recent years. Since VMware Cloud on AWS was first introduced in 2017, the customer base has followed a similar trajectory, with new use cases being uncovered. As a result, customer expectations have also risen. Consumers now want elastic compute; the ability to scale compute independent of storage, elastic performance; the ability to scale IOPS independent of capacity, and elastic capacity; the ability to scale capacity independent of IOPS.
The very nature of VMware Cloud on AWS Hyper-Converged Infrastructure (HCI) nodes has afforded its users greater consolidation and compression ratios, and more flexibility around virtual machine sizing. The first node type introduced was the i3.metal with around 10.37 TiB raw storage, all based on local host NVMe SSD devices. VMware then experimented with an r5.metal node type, offering elastic vSAN backed by the automatic provisioning and management of AWS EBS volumes. The r5 was decommissioned shortly after, and the i3 node was joined by the i3en.metal. The i3enhanced boasted a more powerful specification, including 45.84 TiB of raw capacity per host.
Whilst the i3en.metal node boosted the available storage capacity, it boosted compute with it. For large environments the power of the i3en node is great, but there was still a gap for those environments which were really heavily skewed in the direction of storage consumption, without the need for matching compute overhead.
What is VMware Cloud Flex Storage?
Enter VMware Cloud Flex Storage. Announced today, March 29; a fully VMware-managed and integrated cloud storage service for VMware Cloud on AWS.
VMware Cloud Flex Storage provides disaggregated and elastic storage, catering for capacity-heavy workloads and lower performance needs. By augmenting vSAN as supplemental storage, customers can scale out attached storage without the growth in compute capacity.
NFS datastores of up to 400 TB and up to 150K IOPS can be attached to an SDDC cluster, comprising of either i3 or i3en nodes. Multiple datastores can be attached to a cluster, and a datastore can also be shared across clusters, enabling an initial target into the petabytes. As with the vSAN datastore, data is encrypted at rest by default. Customers can choose between a pay-as-you-go consumption model, or an optional subscription term with a minimum capacity buy in.
VMware Cloud Flex Storage Overview
How Does VMware Cloud Flex Storage Work?
The traditional block storage used by vSAN in the hyper-converged nodes is designed for latency sensitive applications, it handles random transactional workloads well, and is simple to manage or consume. As outlined above, HCI block storage scales per host, as does the cost.
In the back end, VMware Cloud Flex Storage uses AWS S3 with a VMware-managed front end. Object based storage is typically not for latency sensitive workloads, however the additional architecture built around the file system adds caching and I/O optimisation. The scale out file system itself it built on the same technology as VMware Cloud Disaster Recovery. Object storage is also highly durable, resilient across availability zones, low cost, and allows for more granular scaling of capacity, whilst only paying for consumption.
VMware Cloud Flex Storage mounts directly to the hosts using NFS. It resides in a separate VPC maintained by VMware, but connects in using a cross-VPC Elastic Network Interface (ENI). Writes are synchronously written to a HA pair of back end nodes, before being moved into thin-provisioned cloud object storage. There are no customer managed VMs, or cloud gateway type connectivity to worry about. Furthermore, existing vCenter and vROps tooling will be able to monitor performance, latency, IOPS, and availability.
VMware Cloud Flex Storage High Level Architecture
How Do I Access VMware Cloud Flex Storage?
Customers can apply for the early access program by emailing vmcfs_ea at vmware.com. Those accepted onto the program will be provided with a VMware Cloud on AWS SDDC with VMware Cloud Flex Storage for testing at no cost. Although there has been no official date published for general availability, more information can be found on todays blog post Announcing Preview of VMware Cloud Flex Storage.
Managed and as-a-service models are a growing trend across infrastructure consumers. Customers in general want ease and consistency within both IT and finance, for example opting to shift towards OpEx funding models.
For large or enterprise organisations with significant investments in existing technologies, processes, and skills, refactoring everything into cloud native services can be complex and expensive. For these types of environments the strategy has sharpened from Cloud-First to Cloud-Smart. A Cloud-Smart approach enables customers to transition to the cloud quickly where it makes sense to do so, without tearing up roots on existing live services, and workloads or data that do not have a natural progression to traditional cloud.
In addition to the operational complexities of rearchitecting services, many industries have strict regulatory and compliance rules that must be adhered to. Customers may have specific security standards or customised policies requiring sensitive data to be located on-premises, under their own physical control. Applications may also have low latency requirements or the need to be located in close proximity to data processing or back end systems. This is where VMware Local Cloud as a Service (LCaaS) can help combine the key benefits from both public cloud and on-premises environments.
What is VMware Cloud on AWS Outposts?
VMware Cloud on AWS Outposts is a jointly engineered solution, bringing AWS hardware and the VMware Software Defined Data Centre (SDDC) to the customer premises. The relationship with AWS is VMware’s longest standing hyperscaler partnership; with VMware Cloud on AWS the maturest of the multi-cloud offerings from VMware, having been available since August 2017. In October 2021, at VMworld, VMware announced general availability of VMware Cloud on AWS Outposts.
VMware Cloud on AWS Outposts is a fully managed service, as if it were in an AWS location, with consistent APIs. It is built on the same AWS-designed bare metal infrastructure using the AWS Nitro System, assembled into a dedicated rack, and then installed in the customer site ready to be plumbed into power and networking. The term Outpost is a logical construct that is used to pool capacity from 1 or more racks of servers.
The VMware SSDDC overlay, and hardware underlay, comprises of:
VMware vSphere and vCenter for compute virtualisation and management
VMware vSAN for storage virtualisation
VMware NSX-T for network virtualisation
VMware HCX for live migration of virtual machines with stretched Layer 2 capability
3-8 AWS managed dedicated Nitro-based i3.en metal EC2 instances with local SSD storage
Non-chargeable standby node in each rack for service continuity
Fully assembled standard 42U rack
Redundant Top of Rack (ToR) data plane switches
Redundant power conversion unit and DC distribution system (with support for redundant power feeds)
At the time of writing the i3.en metal is the only node type available with VMware Cloud on AWS Outposts. The node specification is as follows:
48 physical CPU cores, with hyperthreading enabled delivering 96 logical cores
768 GiB RAM
45.84 TiB (50 TB) raw capacity per host, delivering up to 40.35 TiB of usable storage capacity per host depending on RAID and FTT configuration
Both scale-out and multi-rack capabilities are currently not available, but are expected. It is also expected that the maximum node count will increase over time, check with your VMware or AWS teams for the most up to date information.
Once the rack is installed on-site, the customer is responsible for power, connectivity into the LAN, and environmental prerequisites such as temperature, humidity, and airflow. The customer is also responsible for the physical security of the Outpost location, however each rack has a lockable door and tamper detection features. Each server is protected by a removable and destroyable Nitro hardware security key. Data on the Outpost is encrypted both at-rest, and in-transit between nodes in the Outpost and back to the AWS region.
Inside the rack, all the hardware is managed and maintained by AWS and VMware, this includes things like firmware updates and failure replacements. VMware are the single support contact for the service regardless of whether the issue is hardware or software related. Additionally, VMware take on the lifecycle management of the full SDDC stack. Customers can run virtual machines using familiar tooling without having to worry about vSphere, vSAN, and NSX upgrades or security patches. Included in the cost ‘per node’ is all hardware within the rack, the VMware SDDC licensing, and the managed service and support.
Existing vCenter environments running vSphere 6.5 or later can be connected in Hybrid Linked Mode for ease of management. Unfortunately for consumers of Microsoft licensing, such as Windows and SQL, Outposts are still treated as AWS cloud infrastructure (in other words not customer on-premises).
Why VMware Cloud on AWS Outposts?
VMware Cloud on AWS Outposts provides a standardised platform with built-in availability and resiliency, continuous lifecycle management, proactive monitoring, and enhanced security. VMware Cloud on AWS delivers a developer ready infrastructure that can now be stood up in both AWS and customer locations in a matter of weeks. Using VMware Cloud on AWS, virtual machines can be moved bi-directionally across environments without the need for application refactoring or conversion.
The initial use case for VMware Cloud on AWS Outposts is existing VMware or VMware Cloud on AWS customers with workloads that must remain on-premises. This could be for regulatory and compliance reasons, or app/data proximity and latency requirements. As features and configurations start to scale, further use cases will no doubt become more prominent.
You can also use other AWS services with Outposts, however you have to make a decision on a per-rack basis whether you are running VMware Cloud on AWS for that rack, or native AWS services. The deployment of the rack is dedicated to one or the other.
VMware Cloud on AWS Outposts Network Connectivity
VMware Cloud on AWS Outposts requires a connection back to a parent VMware Cloud on AWS supported region, or more specifically an availability zone. Conceptually, you can think of the physical VMware Cloud on AWS Outposts installation as an extension of that availability zone. The connection back to AWS is used for the VMware Cloud control plane, also known as the service link.
The service link needs to be a minimum of 1Gbps with a maximum 150ms latency, either using a Direct Connect, or over the public internet using a VPN. Public Amazon Elastic IPs are used for the service link endpoint. Although the VMware Cloud on AWS Outposts service is not designed to operate in environments with limited or no connectivity, in the event of a service link outage the local SDDC will continue functioning as normal. This includes vCenter access and VM operations. A service link outage will prevent monitoring and access to configurations or other functionality from the VMware Cloud portal.
There is no charge for data transfer from VMware Cloud on AWS Outposts back to the connected region. Data transfer from the parent availability zone to the VMware Cloud on AWS Outposts environment will incur the standard AWS inter-AZ VPC data transfer charges.
Customers can use the connected VPC in the customer managed AWS account to access native AWS services in the cloud, either using the Elastic Network Interface (ENI) or VMware Transit Connect.
The Local Gateway (LGW) is an Outposts-specific logical construct used to route traffic to and from the existing on-premises network. This traffic stays within the local site allowing for optimised traffic flow and low latency communication. There is no data transfer cost for data traversing the LGW, either out to the internet or to your local network.
Extensive workshops are carried out between VMware and/or AWS and the customer
If the customer is a new VMware Cloud customer then a new org is created with a unique org ID
Customer pre-req: a VMware Cloud account and org is required
The customer receives an invite to join the VMware Cloud on AWS Outposts service through email
The customer places an order via the VMware Cloud console
Customer pre-req: customer AWS account with VPC and dedicated subnet, if using a private VIF for Direct Connect, then the VIF should already be created in the customer AWS account
Customer pre-req: knowledge of the facility, power, and network setup*
Customer pre-req: knowledge of desired instance count and configuration
The customer receives and responds to the request to submit logical networking information
This information will be gathered during the customer workshop, the service link requires a dedicated VLAN and /26 subnet, the SDDC management network requires a dedicated /23 minimum, and an additional CIDR block needs allocating for compute networks
AWS schedule and carry out a site survey
AWS builds and delivers the rack
Final onsite provisioning is carried out by AWS and validated by VMware
VMware notify the customer the environment is ready to use
The SDDC is provisioned through automated workflows as instructed by the customer
*full details of the facility, power, and network requirements for the local site can be found in the AWS Outposts requirements page
In my day job I am often asked about the use of cloud for disaster recovery. Some organisations only operate out of a single data centre, or building, while others have a dual-site setup but want to explore a third option in the cloud. Either way, using cloud resources for disaster recovery can be a good way to learn and validate different technologies, potentially with a view to further migrations as data centre and hardware contracts expire.
This post takes a look at the different cloud-based disaster recovery options available for VMware workloads. It is not an exhaustive list but provides some ideas. Further work will be needed to build a resilient network architecture depending on the event you are looking to protect against. For example do you have available network links if your primary data centre is down, can your users and applications still route to private networks in the cloud, are your services internet facing allowing you to make your cloud site the ingress and egress point. As with any cloud resources, in particular if you are building your own services, a shared security model applies which should be fully understood before deployment. Protecting VMware workloads should only form part of your disaster recovery strategy, other dependencies both technical and process will also play a part. For more information on considering the bigger picture see Disaster Recovery Strategy – The Backup Bible Review.
Concepts
DRaaS (Disaster Recovery as a Service) – A managed service that will typically involve some kind of data replication to a site where the infrastructure is entirely managed by the service provider. The disaster recovery process is built using automated workflows and runbooks; such as scaling out capacity, and bringing online virtual machines. An example DRaaS is VMware Cloud Disaster Recovery which we’ll look at in more detail later on.
SaaS (Software as a Service) – An overlay software solution may be able to manage the protection of data and failover, but may not include the underlying infrastructure components as a whole package. Typically the provider manages the hosting, deployment, and lifecycle management of the software, but either the customer or another service provider is responsible for the management and infrastructure of the protected and recovery sites.
IaaS and PaaS (Infrastructure as a Service and Platform as a Service) – Various options exist around building disaster recovery solutions based on infrastructure or platforms consumed from a service provider. This approach will generally require more effort from administrators to setup and manage but may offer greater control. An example is installing VMware Site Recovery Manager (self-managed) to protect virtual machines running on VMware-based IaaS. Alternatively third party backup solutions could be used with cloud storage repositories and cloud hosted recovery targets.
Hybrid Cloud – The VMware Software Defined Data Centre (SDDC) can run on-premises and overlay cloud providers and hyperscalers, delivering a consistent operating platform. Disaster recovery is one of the common use cases for a hybrid cloud model, as shown in the whiteboard below. Each of the solutions covered in this post is focused around a hybrid cloud deployment of VMware software in an on-premises data centre and in the cloud.
Hybrid Cloud Use Cases
VMware Cloud Disaster Recovery
VMware Cloud Disaster Recovery (VCDR) replicates virtual machines from on-premises to cloud based scale-out file storage, which can be mounted to on-demand compute instances when required. This simplifies failover to the cloud and lowers the cost of disaster recovery. VCDR allows for live mounting of a chosen restore point for fast recovery from ransomware. Recently ransomware has overtaken events like power outages, natural disasters, human error, and hardware failure as the number one cause of disaster recovery events.
VCDR uses encrypted AWS S3 storage with AWS Key Management Service (KMS) as a replication target, protecting virtual machines on-premises running on VMware vSphere. There is no requirement to run the full SDDC / VMware Cloud Foundation (VCF), vSAN, or NSX at the replication source site. If and when required, the scale-out file system is mounted to compute nodes using VMware Cloud (VMC) on AWS, without the need to refactor or change any of the virtual machine file formats. VCDR also includes built-in audit reporting, continuous healthchecks at 30 minute intervals, and test failover capabilities.
VMware Cloud on AWS provides the VMware SDDC as a managed service running on dedicated AWS bare-metal hardware. VMware manage the full infrastructure stack and lifecycle management of the SDDC. The customer sets security and access configuration, including data location. Currently VCDR is only available using VMware Cloud on AWS as the target for cloud compute, with the following deployment options:
On Demand – virtual machines are replicated to the scale-out file storage, when disaster recovery is invoked an automated SDDC deployment is initiated. When the SDDC is ready the file system is mounted to the SDDC and virtual machines are powered on. Typically this means a Recovery Time Objective (RTO) of around 4 hours. For services that can tolerate a longer RTO the benefit of this deployment model is that the customer only pays for the storage used in the scale-out storage, and then pays for the compute on-demand should it ever be needed.
Pilot Light – a small VMware Cloud on AWS environment exists, typically 3 hosts. Virtual machines are replicated to the scale-out file storage, when disaster recovery is invoked the file system is instantly mounted to the existing SDDC and virtual machines are powered on. Depending on the number of virtual machines being brought online, the SDDC automatically scales out the number of physical nodes. This brings the RTO time down to as little as a few minutes. The customer is paying for the minimum VMware Cloud on AWS capacity to be already available but this can be scaled out on-demand, offering significant cost savings on having an entire secondary infrastructure stack.
VMware Cloud Disaster Recovery
The cloud-based orchestrator behind the service is provided as SaaS, with a connector appliance deployed on-premises to manage and encrypt replication traffic. After breaking replication and mounting the scale-out file system administrators manage virtual machines using the consistent experience of vSphere and vCenter. Startup priorities can be set to ensure critical virtual machines are started up first. At this point virtual machines are still running in the scale-out file system, and will begin to storage vMotion over to the vSAN datastore provided by the VMware Cloud on AWS compute nodes. The storage vMotion time can vary depending on the amount of data and number of nodes (more nodes and therefore physical NICs provides more network bandwidth), however the vSAN cache capabilities can help elevate any performance hit during this time. When the on-premises site is available again replication reverses, only sending changed blocks, ready for failback.
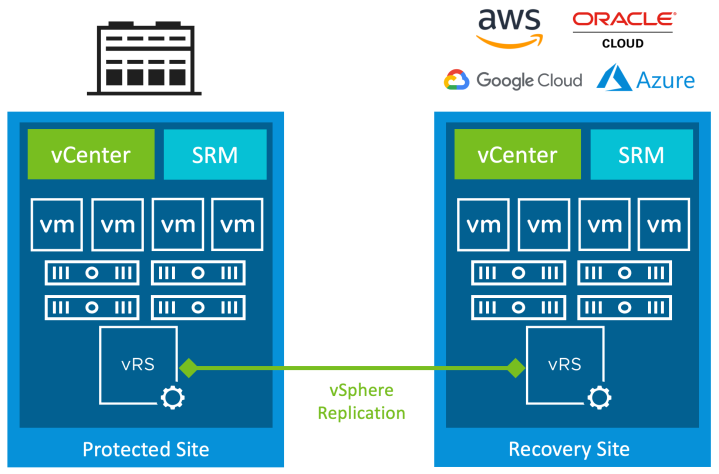
VMware Site Recovery Manager (SRM) has been VMware’s main disaster recovery solution for a number of years. SRM enables policy-driven automation of virtual machine failover between sites. Traditionally SRM has been used to protect vSphere workloads in a primary data centre using a secondary data centre also running a VMware vSphere infrastructure. One of the benefits of the hybrid cloud model utilising VMware software in a cloud provider like AWS, Azure, Google Cloud, or Oracle Cloud, is the consistent experience of the SDDC stack; allowing continuity of solutions like SRM.
SRM in this scenario can be used with an on-premises data centre as the protected site, and a VMware stack using VMware Cloud on AWS, Azure VMware Solution (AVS), Google Cloud VMware Engine (GCVE), or Oracle Cloud VMware Solution (OCVS) as the recovery site. SRM can also be used to protect virtual machines within one of the VMware cloud-based offerings, for example failover between regions, or even between cloud providers. Of these different options Site Recovery Manager can be deployed and managed by the customer, whereas VMware Cloud on AWS also offers a SaaS version of Site Recovery Manager; VMware Site Recovery, which is covered in the next section.
VMware Site Recovery
SRM does require the recovery site to be up and running but can still prove value for money. Using the hybrid cloud model infrastructure in the cloud can be scaled out on-demand to fulfil failover capacity, reducing the amount of standby hardware required. The difference here is that vSphere Replication is replicating virtual machines to the SDDC vSAN datastore, whereas VCDR replicates to a separate scale-out file system. The minimum number of nodes may be driven by storage requirements depending on the amount of data being protected. The recovery site could also be configured active/active, or run test and dev workloads that can be shut down to reclaim compute capacity. Again storage overhead is a consideration when deploying this type of model. Each solution will have its place depending on the use case.
SRM allows for centralised recovery plans of VMs and groups of VMs, with features like priority groups, dependencies, shut down and start up customisations, including IP address changes using VMware Tools, and non-disruptive recovery testing. If you’ve used SRM before the concept is the same for using a VMware cloud-based recovery site as a normal data centre; an SRM appliance is deployed and registered with vCenter to collect objects like datastores, networks, resource pools, etc. required for failover. If you haven’t used SRM before you can try it for free using either the VMware Site Recovery Manager Evaluation, or VMware Site Recovery Hands-on Lab. Additional information can be found at the VMware Site Recovery Manager Solution and VMware Site Recovery Manager Documentation pages.
VMware Site Recovery
VMware Site Recovery is the same product as Site Recovery Manager, described above, but in SaaS form. VMware Site Recovery is a VMware Cloud based add-on for VMware Cloud on AWS. The service can link to Site Recovery Manager on-premises to enable failover to a VMware Cloud on AWS SDDC, or it can provide protection and failover between SDDC environments in different VMware Cloud on AWS regions. At the time of writing VMware Site Recovery is not available with any other cloud providers. As a SaaS solution VMware Site Recovery is naturally easy to enable, it just needs activating in the VMware Cloud portal. You can find out more from the VMware Site Recovery Solution page.
Closing Notes
For more information on the solutions listed see the VMware Disaster Recovery Solutions page, and check in with your VMware account team to understand the local service provider options relevant to you. There are other solutions available from VMware partners and backup providers. Your existing backup solution for example may offer a DRaaS add-on, or the capability to backup or replicate to cloud storage which can be used to build out your own disaster recovery solution in the cloud.
The table below shows a high level comparison of the difference between VMware Cloud Disaster Recovery and Site Recovery Manager offerings. As you can see there is a trade off between cost and speed of recovery, there are use cases for each solution and in some cases maybe both side by side. Hopefully in future these products will fully integrate to allow DRaaS management from a single interface or source of truth where multiple Recovery Point Objective (RPO) and RTO requirements exist.
Solution
Service Type
Replication
Failover
RPO
Pricing
VMware Cloud Disaster Recovery
On demand DRaaS
Cloud based file system
Live mount when capacity is available
~4 hours
Per VM, per TiB of storage, list price is public here. VMC on AWS capacity may be needed*
VMware Site Recovery
Hot DRaaS
Directly to failover capacity
Fast RTOs using pre-provisioned failover capacity
As low as 5 minutes with vSAN at the protected site, or 15 minutes without vSAN
Per VM, list price is public here. vSphere Replication is also needed**
VMware Site Recovery Manager
Self-managed
Directly to failover capacity
Fast RTOs using pre-provisioned failover capacity
As low as 5 minutes with vSAN at the protected site, or 15 minutes without vSAN
Per VM, in packs of 25 VMs. vSphere Replication is also needed**
VMware Cloud Disaster Recovery (VCDR) and Site Recovery Manager (SRM) side-by-side comparison
*VMware Cloud on AWS capacity is needed depending on the deployment model, detailed above. For pilot light a minimum of 3 nodes are running all the time, these can be discounted using 1 or 3 year reserved instances. For on-demand if failover is required then the VMC capacity is provisioned using on-demand pricing. List price for both can be found here, but VMware also have a specialist team that will work out the sizing for you.
**vSphere Replication is not sold separately but is included in the following versions of vSphere: Essentials Plus, Standard, Enterprise, Enterprise Plus, and Desktop.