Introduction
Today, June 28 2022, VMware announced vSphere+ and vSAN+; subscription based offerings of their enterprise compute and storage virtualisation solutions.
First mooted during VMworld 2021, Project Arctic promised to deliver a cloud operating model to customer’s data centre and edge locations. At a high level, that means hands-off maintenance, proactive monitoring, pay-as-you-grow consumption, subscription billing, and a shift to opex funding.
Furthermore, vSphere subscriptions allow VMware to integrate products and services as features. VMware Cross-Cloud Services will enable on-demand scale out capacity and disaster recovery capabilities. We know from the general industry shift towards Software-as-a-Service (SaaS), that the frequency of development cycles and feature delivery are increased, resulting in faster and greater value to the end customer.
The release of vSphere+ and vSAN+ is VMware’s first iteration of the Project Arctic feature set, with more capabilities and products to be added. In this release, customers can expect to benefit from simplified operations, faster time to value, and future investment in IT strategy. Find out more at the vSphere+ microsite.
What is vSphere+?
The launch of vSphere+ and vSAN+ provides customers with a subscription to compute and storage virtualisation solutions. It is aimed at organisations wanting to retain an on-premises footprint, either data centre or edge, with a consistent operating experience to their cloud infrastructure.
This means it is easy for brownfield environments to adopt, and improve their operational processes and security posture. vSphere+ is more than just a subscription to an existing product, it also offers administrators the following benefits:
- Aggregate vCenter Servers and global infrastructure into a single view
- VMware assisted lifecycle management, initially for vCenter Server
- Significantly lower maintenance touch, and reduced down time with vCenter Server Reduced Downtime Upgrades
- Faster access to new features, fixes, and security patches
- Check for configuration drift, security issues, consistent errors, and update status across all vCenters and clusters
- Enable access to the embedded Tanzu services for build, run, and manage, of modern container based applications
- Global monitoring of VMware environments, see examples in this vSphere+ Tech Zone blog
- Deploy virtual machines to multiple platforms from anywhere with the new cloud admin interface
- Co-term licensing and support across VMware environments with flexible scaling options
- Removes the need for individual vCenter Server licenses (see the licensing section below)
vSphere+ introduces a new cloud admin portal, this is an additional SaaS control plane, which interacts with a gateway server on-premises. The sections below go into more technical detail, but the vCenter Servers do not talk directly out to the Internet, and no workloads or components are moved to the cloud as part of this operating model.
The term cloud-like operating model relates to features like the one-click vCenter updates, one-click Kubernetes cluster enablement (a cloud native container orchestration tool), and flexible subscription, or operating expenditure, nature of the service.
Many customers want the benefits of cloud, namely flexible consumption, minimal maintenance, built-in resilience, developer agility, and anywhere management. They may also need to retain some on-premises infrastructure, for data privacy, security, or sovereignty reasons, and for high-performance or low-latency requirements. The introduction of vSphere+ aims to provide these cloud benefits in the remaining data centre or edge locations.
You can read more about the admin services and developer services available through the new cloud portal, as well as the full range of benefits introduced by vSphere+, in the blog VMware vSphere+ Introducing The Multi-Cloud Workload Platform.

How Does vSphere+ Work?
Beyond the licensing information in the section below, there are some further technical considerations and clarifications.
Since the vSphere infrastructure on-premises are already deployed, there is no impact to those existing vSphere, vCenter, or vSAN environments. The vCenter Server needs to be running a minimum of version 7.0.3, so there may be a vCenter upgrade, but there is no vSphere/ESXi update required. vCenter 7.0.3 is backwards compatible with vSphere 6.5 onwards, although note that vSphere 6.x reaches end of support on 15 October 2022.
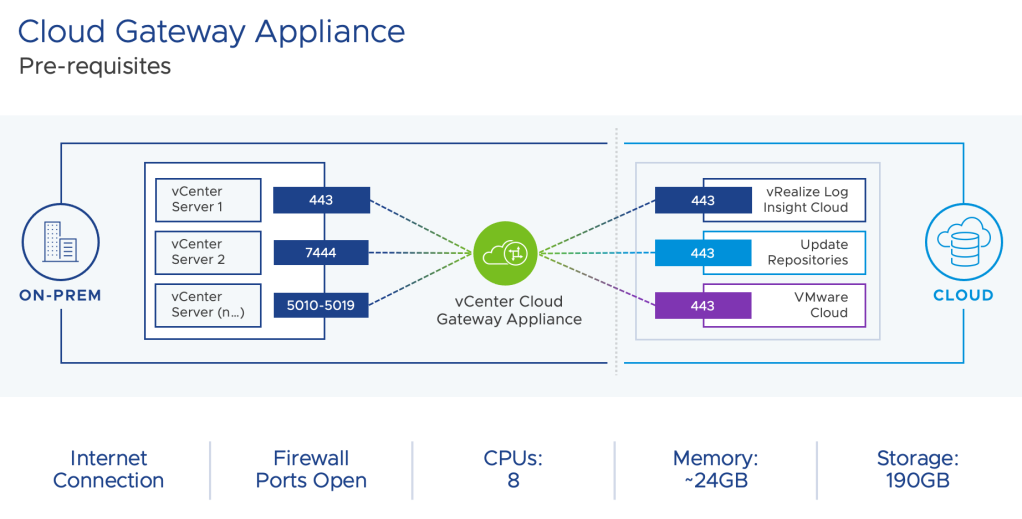
A Cloud Gateway appliance is used to connect the on-premises vSphere estate with the VMware Cloud control plane. The appliance is a standard OVA, here is some additional information:
- The appliance needs 8 CPU, ~24 GB RAM, 190 GB disk, and a secondary IP address
- The appliance does not need backing up or HA deployment
- The appliance is stateless and can easily be deleted and re-deployed in the event of any issues
- There is an admin interface for setting minimal configuration such as Internet proxy
- Lifecycle management of the appliance is automated from the cloud control plane
- There is a maximum latency requirement of 100ms from the vCenter to the gateway appliance, and from the gateway to the cloud portal
- The gateway appliance has limited access to the customer environment
- Communication between the gateway appliance and cloud portal is fully encrypted and there is no VPN requirement
- The gateway appliance needs outbound HTTPS connectivity only, and there are no network charges
- The gateway appliance also uploads logs to VMware support, accelerating troubleshooting during incidents
- The gateway appliance is the point of authentication, and no usernames and passwords are transmitted to the cloud
- Data is not shared with third parties or used for marketing purposes
- You can have multiple gateway appliances, with up to 4 vCenter Servers per gateway (note that there is no change in vCenter and vSphere configuration maximums)
Subscription services for vSphere+ and vSAN+ can be activated from the cloud portal. Host billing and licensing is also managed here, with no need to install license keys. Outside of vCenter lifecycle management, and subtle differences like the removal of license keys, there is no day-to-day change in how you manage and operate the vSphere environment.
If the gateway appliance, or Internet connection, is lost the vSphere environment continues to work as normal. If the gateway has not connected to the cloud control plane after 24 hours then vSphere administrators will see advisory messages bringing this to their attention, on the login page.
For vCenter updates, VMware do not apply updates automatically without informing the customer. The customer has complete control over the planning and scheduling of updates across vCenter Servers. When a new update is available a notification is generated, and the customer chooses when to have the update applied. The inventory will apply a traffic light system for vCenter instances depending on how many versions behind the latest release they might be.
How Does vSphere+ Licensing Work?
Previously, virtualisation customers would shell out a large upfront cost for perpetual licenses they would own outright. To deliver full value the perpetual license was supplemented with SnS (Support and Subscription), adding technical support, and access to the latest updates and security patches.
With perpetual licenses and SnS renewals, the vCenter Server license (per instance) and vSphere license (per CPU) were purchased separately. The vCenter Server provides overarching management capabilities, including enterprise features like resource balancing and High Availability (HA). The hypervisor vSphere, or ESXi, is installed on physical servers and facilitates compute virtualisation.
From July 2022, customers can upgrade to subscription based offerings of vSphere+ and vSAN+ rather than the traditional SnS renewal. You may have seen a similar early access program, branded vSphere Advantage. Both vSphere Advantage and Project Arctic are officially named vSphere+ at launch.
The vSphere+ license will include vSphere (for the core count stipulated), vCenter Server (for unlimited instances), the new vSphere admin service (SaaS Based), the Tanzu Standard runtime, and Tanzu Mission Control Essentials. Tanzu services enable build, run, and manage for modern applications through the use of containers and Kubernetes orchestration, directly within the hypervisor.
The version of vSphere included with vSphere+ has feature parity with vSphere Enterprise Plus, and production support. You can view the full vSphere Enterprise Plus feature set here.
Once a vCenter Server is registered with the cloud control plane all connected hosts and associated CPUs will be counted as licensed physical cores. Note that 16 cores make up 1 CPU, which is a change to the existing perpetual limit where 1 CPU is currently valid for up to 32 cores. As physical servers are added or removed, the corresponding core count is increased or decreased.
Core commits can be made for 1, 3, or 5 year periods, with additional cores billed as overage (or the commit level increased). Any overage is calculated per hour and billed in arrears at the end of the month. A customer can run a combination of vSphere+ and perpetual vSphere, however they need to be registered with different vCenter Servers.
How Does vSAN+ Licensing Work?
The vSAN+ license is available as an add-on to vSphere+, it cannot be purchased separately. As the license is an add-on it automatically co-terms with the vSphere+ duration. Commit and overage terms are the same as vSphere+.
Using vSAN+, customers benefit from centralised management, global inventory monitoring, and global alert status from the cloud console. Existing vSAN datastores are integrated into the cloud portal virtual machine provisioning workflow, to allow deployment of workloads to a vSAN cluster from anywhere. You can read more in the Introducing vSAN+ blog.
The vSAN+ license has feature parity with vSAN Enterprise, you can view the full vSAN feature list here. At initial release, lifecycle management only covers vCenter Server. It is likely that in the future vSphere/vSAN lifecycle management may also be added to Project Arctic.





